서울시의 행정동별 평균 소득 및 소비 데이터셋을 우연히 발견하여 시각화해보면 좋겠다 싶어 만들어보았어요.
Visualizations/Seoul_2023_Dong_income_expenditure에 사용한 R script가 있으니 확인해 보아도 좋겠습니다. 아래에서는 핵심 코드를 살펴봅시다.
Geospatial data의 시각화에 대한 기본적인 내용은 Claus O. Wilke의 Fundamentals of Data Visualization에서 살펴보기를 추천해요.
Dataset
- 서울시 행정동별 평균 소득 및 소비 데이터셋 (이하 ‘서울시 데이터셋’)
- “서울 열린데이터 광장”에서 제공하는 서울시 상권분석서비스(소득소비-서울시)의 .csv 파일을 다운로드하여 사용함.
- 최신수정일자 2023.11.13일자의 데이터
- License: CC BY
## Data Import--------------------------------------------- raw_seoul <- read.csv("./Seoul_income_expendit_dong.csv",fileEncoding = "euc-kr")
- 서울시 구역의 도형 데이터셋 (이하 ‘지도 데이터셋’)
- “주소기반산업지원서비스”의 “제공하는 주소” - “구역의 도형” - 2022년 11월 자료 선택하여 수령 (“구역의도형_전체분_서울특별시.zip”) 후 사용함.
- “TL_SCCO_GEMD.shp”이 서울시 행정동의 구역의 도형 shape file임. .dbf 파일과 .shx 파일과 동일 directory에 있어야 함을 유의.
- “TL_SCCO_SIG.shp”이 서울시 구의 구역의 도형 shape file임. 마찬가지로 .dbf 파일과 .shx 파일과 동일 directory에 있어야 함.
- shp, dbf, shx, prj 파일과 CRS, EPSG에 관해서는 한국R사용자회가 작성한 지리정보 - R (공간통계를 위한 데이터 사이언스)를 참고하자.
# Seoul Dong polygon Data
map_seoul <- st_read("./Shapes/TL_SCCO_GEMD.shp", options = "ENCODING=euc-kr") # Data last updated in 2022-11
map_seoul<- sf::st_set_crs(map_seoul, 5179) # EPSG가 NA인 상태. EPSG를 5179로 맞춰준다.
# Seoul Gu polygon Data
map_seoul_gu <- st_read("./Shapes/TL_SCCO_SIG.shp", options = "ENCODING=euc-kr")# Map at 2022-11
map_seoul_gu <- sf::st_set_crs(map_seoul_gu, 5179) # EPSG가 NA인 상태. EPSG를 5179로 맞춰준다.
Data Wrangling
- 필요한 데이터 선택 후 간단히 다듬기
- Column name을 영어로 변환합니다. R에서 한글을 사용하다보면 가끔 오류가 생길 때가 있어서요.
seoul <- raw_seoul colnames(seoul) <- c("quarter", "dong_code", "dong_name", "mean_income", "income_interval", "sum_e", "grocery_e", "clothes_e", "life_e", "medical_e", "transport_e", "edu_e", "play_e", "hobby_e", "etc_e", "food_e") - 2023년 1분기 조건에 부합하는 row만 선택합니다.
seoul_20231 <- dplyr::filter(seoul, quarter == 20231) |> as_tibble() - 서울시 데이터셋의 EMD_CD는 지도 데이터의 EMD_CD에서 끝 두자리 00이 생략된 상태입니다. EMD_CD로 두 데이터를 합치기 위해 서울시 데이터셋 EMD_CD column 끝에 “00”을 붙입시다. 참고로 EMD_CD는 ‘읍면동’에 부여되는 고유한 코드입니다.
seoul_20231$EMD_CD <- as.character(paste0(seoul_20231$dong_code, "00"))
- Column name을 영어로 변환합니다. R에서 한글을 사용하다보면 가끔 오류가 생길 때가 있어서요.
- 두 데이터셋 사이의 자료 비교 후 적절히 변경하기
- 서울시 데이터셋은 “개포3동”, “상일제1동”, “상일제2동”의 데이터를 포함하지 않고 있는데, 이는 데이터가 행정동 분리와 명칭 변경 이전에 작성되었기 때문인 것으로 보입니다. 변경된 데이터셋은 새로운 객체에 저장합니다.
seoul_20231_updated <- seoul_20231 - 서울시 데이터셋의 “일원2동”은 2022년 12월 23일에 “개포3동”으로 명칭이 변경되었습니다 (강남구청). 이에 따라 서울시 데이터셋의 “dong_name”변수를 “일원2동”에서 “개포3동”으로 변경하고 해당 “dong_code”와 “EMD_CD” 변수 또한 변경하여 “seoul_20231_updated” 객체에 저장합니다.
# 일원2동 -> 개포3동 renamed seoul_20231_updated[seoul_20231_updated$dong_code == 11680740, 17] <- "1168067500" # 일원2동 -> 개포3동 renamed seoul_20231_updated[seoul_20231_updated$dong_code == 11680740, 3] <- "개포3동" - 서울시 데이터셋의 “상일동”은 2021년 07월 01일에 “상일제1동”으로 명칭이 변경되었습니다 (상일1동 주민센터). 이에 따라 서울시 데이터셋의 “dong_name”변수를 “상일동”에서 “상일제1동”으로 변경하고 해당 “dong_code”와 “EMD_CD” 변수 또한 변경하여 “seoul_20231_updated” 객체에 저장합니다.
# 상일동 -> 상일제1동 renamed seoul_20231_updated[seoul_20231_updated$dong_code == 11740520, 17] <- "1174052500" # 상일동 -> 상일제1동 renamed seoul_20231_updated[seoul_20231_updated$dong_code == 11740520, 3] <- "상일제1동" - 서울시 데이터셋의 “강일동”의 남쪽 지역은 2021년 07월 01일에 “상일제2동”으로 분리되었습니다 (연합뉴스). 이에 따라 “dong_name”을 “상일제2동”으로 하고, “상일제2동”의 “dong_code”와 “EMD_CD”를 갖는 새로운 행을 “seoul_20231_updated” 객체에 추가하였습니다. 이때 “상일제2동”의 소득-지출 데이터는 “강일동”의 데이터를 복사하여 그대로 붙여넣었습니다.
seoul_20231_updated[nrow(seoul_20231_updated)+1, ] <- NA # New empty row added # 상일제2동 row added (South region of 강일동 became 상일제2동) seoul_20231_updated[nrow(seoul_20231_updated), 1:3] <- list(20231, 11740526,"상일제2동") # 상일제2동 data is the same as 강일동. seoul_20231_updated[nrow(seoul_20231_updated), 4:16] <- seoul_20231_updated[283, 4:16] # 상일제2동 EMD_CD added. seoul_20231_updated[nrow(seoul_20231_updated), 17] <- "1174052600"
- 서울시 데이터셋은 “개포3동”, “상일제1동”, “상일제2동”의 데이터를 포함하지 않고 있는데, 이는 데이터가 행정동 분리와 명칭 변경 이전에 작성되었기 때문인 것으로 보입니다. 변경된 데이터셋은 새로운 객체에 저장합니다.
- 서울시 데이터셋 (seoul_20231_updated)과 지도 데이터셋 (map_seoul)을 left_join()으로 병합합니다. 두 데이터의 공통으로 있는 EMD_CD를 기준으로 합칩니다.
# Combine sf and data combined_data <- left_join(map_seoul, seoul_20231_updated, by = "EMD_CD") # The order of x and y matters. combined_data |> filter(is.na(dong_code)) # To check if any row is missing
Plot with {ggplot2}
- 시각화에는
{ggplot2},{ggrepel},{ggsflabel},{ggtext},{showtext}패키지를 사용하였습니다. ggplot 스크립트를 한 줄씩 살펴봅시다. 먼저 ggplot() 객체를 만들고, + 기호로 다른 요소들을 덧붙여 줍니다.
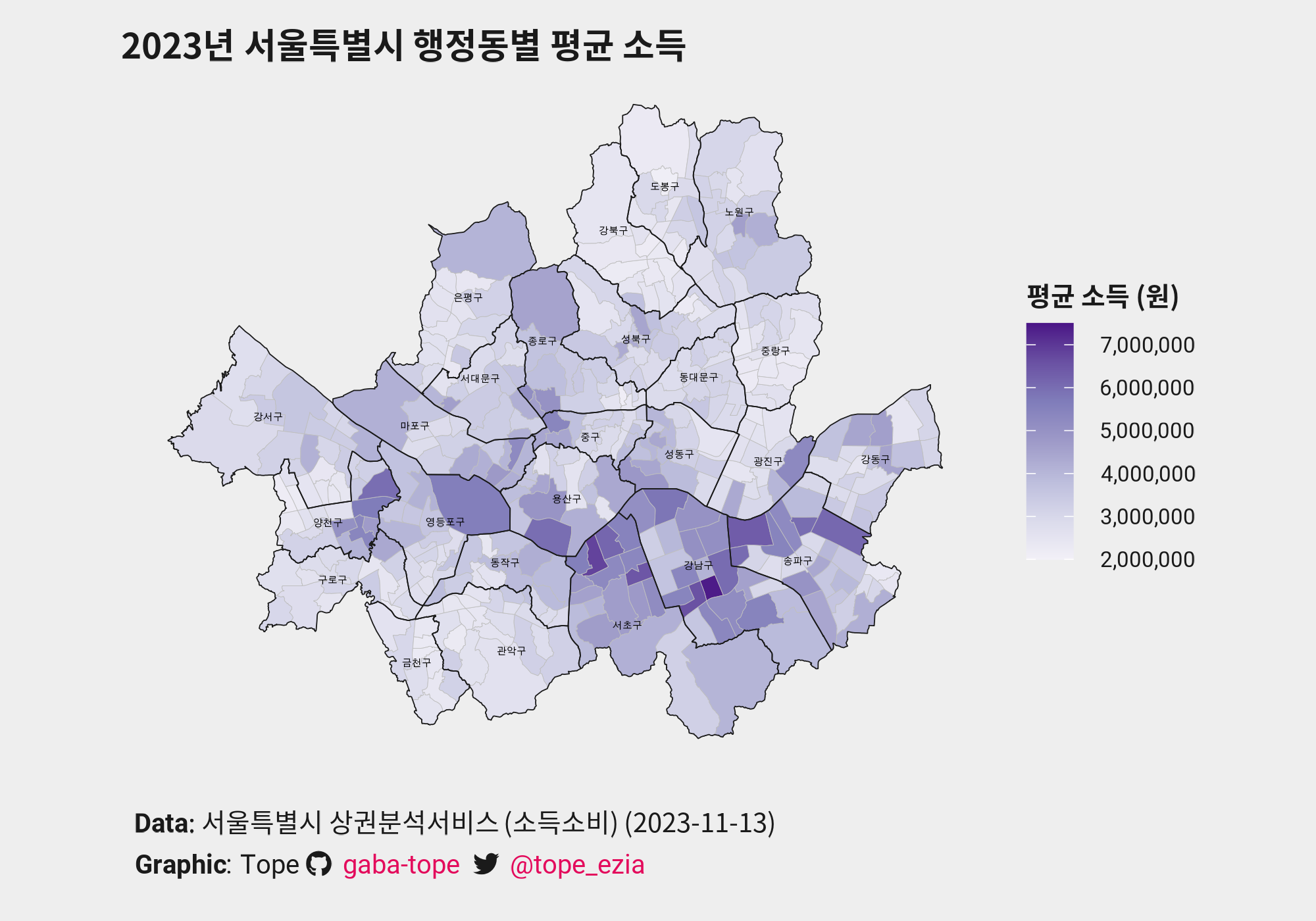
seoul_plot <- ggplot() + - 행정동별 평균 소득 차이에 따라 색을 다르게 칠합니다. 그것이 choropleth plot이니까요~!
geom_sf(data = combined_data, aes(fill = mean_income), color = major_grid_col, linewidth = 0.1) + - 그 위에 행정구역인 ‘구’가 그려져있다면 지도를 읽기 한층 쉬워질 것 같습니다.
geom_sf(data = map_seoul_gu, color = text_col, alpha = 0) + - 어떤 색을 사용할까요? Colorbrewer에서 제공하는 “Purples” 팔레트를 사용합니다. scale_fill_distiller() 함수를 덧붙입시다. Legend의 limit과 break을 설정합니다.
scale_fill_distiller(palette = "Purples", direction = 1, labels = scales::label_comma(), limits = c(2000000, 7500000), breaks = seq(2000000, 7500000, 1000000)) + - 각 구의 이름을 지도에 표기합니다.
geom_sf_text()와geom_sf_text_repel()로 적절한 위치에 추가합시다. - Title, caption, legend title 등을 추가하고 plot theme도 원하는대로 정하여 덧붙입니다.
labs(title = title_map, caption = cap_map, fill = legend_map)+ map_theme - 완성된 plot을 저장합니다.
ggsave(file="seoul_plot.png", plot = seoul_plot, width = 2000, height= 1400, units = 'px', dpi = 300)